Aprendiendo a instalar WordPress
Un tutorial paso a paso para ayudarte a instalar WordPress. Da el primer paso para comenzar tus proyectos webs y darle vida a esa idea

Los algoritmos de ordenación son esenciales en la informática moderna. Desde la organización de bases de datos hasta la optimización de procesos en inteligencia artificial, estos métodos permiten ordenar datos de manera eficiente para mejorar el rendimiento de los sistemas.
Existen diferentes métodos de ordenación, cada uno con ventajas y desventajas según el caso de uso. Entre los más conocidos se encuentran Bubble Sort, QuickSort, Merge Sort, HeapSort, Counting Sort y Radix Sort. Algunos, como Insertion Sort y Selection Sort, son fáciles de entender pero poco eficientes en grandes volúmenes de datos, mientras que otros, como QuickSort, se utilizan en aplicaciones de alto rendimiento debido a su velocidad.
En este artículo, exploraremos los algoritmos de ordenamiento más utilizados, sus características y cuándo es recomendable utilizar cada uno. Si alguna vez te has preguntado cuál es el mejor algoritmo de ordenación según la situación, aquí encontrarás una guía completa para entender sus ventajas y diferencias.

Tabla de contenidos
Un algoritmo de ordenación es un conjunto de pasos diseñados para organizar elementos en un orden específico, generalmente ascendente o descendente. Son fundamentales en el manejo de datos, ya que optimizan procesos como la búsqueda y el análisis eficiente de información.
Imagina que tienes una lista desordenada de números:
[8, 3, 1, 6, 5]
Si por ejemplo aplicamos un algoritmo de ordenamiento como Bubble Sort para ordenar ascendentemente nuestra lista de números nos quedaría:
[1, 3, 5, 6, 8]
Este mismo concepto se aplica a listas de nombres, fechas y otros tipos de datos en sistemas reales.
Para elegir el mejor algoritmo de ordenamiento, es clave conocer sus principales características:

Los algoritmos de ordenación se pueden clasificar de diversas formas según su funcionamiento y eficiencia. A continuación, exploramos sus principales categorías.
Los algoritmos de ordenación pueden dividirse en dos grupos principales según cómo procesan los datos:
Algoritmos de comparación
Utilizan comparaciones entre elementos para determinar su posición en la lista. Son los más comunes y aplicables a cualquier tipo de datos.
Ejemplos: QuickSort, Merge Sort, HeapSort, Bubble Sort.
Algoritmos no comparativos
No dependen de comparaciones, sino de propiedades específicas de los datos (como la distribución de valores). Suelen ser más eficientes en casos concretos.
Ejemplos: Counting Sort, Radix Sort, Bucket Sort.
El rendimiento de los algoritmos varía según su complejidad y uso práctico.
Algoritmos de ordenación simple
Son fáciles de implementar, pero ineficientes en listas grandes debido a su alta complejidad temporal.
Ejemplos: Bubble Sort, Selection Sort, Insertion Sort.
Algoritmos de ordenación eficiente
Son utilizados en aplicaciones reales por su alto rendimiento, especialmente con grandes volúmenes de datos.
Ejemplos: QuickSort, Merge Sort, HeapSort.
Los algoritmos de ordenación simple son fáciles de entender e implementar, pero su rendimiento no es óptimo en grandes volúmenes de datos. Aun así, son fundamentales para comprender cómo funciona la ordenación y pueden ser útiles en casos específicos.
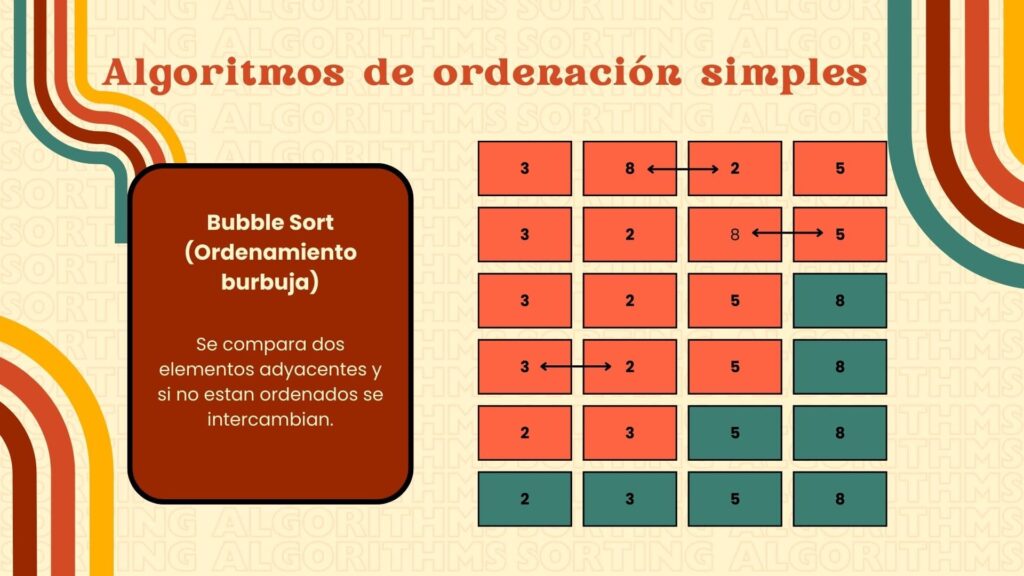
¿Cómo funciona el algoritmo Bubble Sort?
Bubble Sort recorre repetidamente la lista, comparando elementos adyacentes y intercambiándolos si están en el orden incorrecto. Este proceso hace que los elementos más grandes “floten” hacia el final de la lista en cada pasada. Se repite hasta que no se necesitan más intercambios, lo que indica que la lista está ordenada.
Análisis de complejidad de Bubble Sort
La eficiencia de Bubble Sort depende del estado inicial de la lista:
Aunque es sencillo de implementar, Bubble Sort realiza muchos más intercambios que otros algoritmos como Selection Sort, por lo que no es el más eficiente para listas grandes.

¿Cómo funciona el algoritmo Selection Sort?
Selection Sort divide la lista en dos partes: una ordenada y otra desordenada. En cada iteración, busca el elemento más pequeño en la parte desordenada y lo intercambia con el primer elemento de esa sección. Se repite este proceso hasta que toda la lista esté ordenada.
Análisis de complejidad de Selection Sort
Selection Sort siempre realiza el mismo número de comparaciones sin importar el estado inicial de la lista:
Diferencias clave entre Selection Sort y Bubble Sort
Aunque ambos tienen la misma complejidad, Selection Sort es más eficiente en términos de intercambios, ya que solo hace uno por cada iteración (en lugar de múltiples como Bubble Sort). Sin embargo, Bubble Sort puede detenerse antes si la lista ya está ordenada, lo que le da una ventaja en listas casi ordenadas.
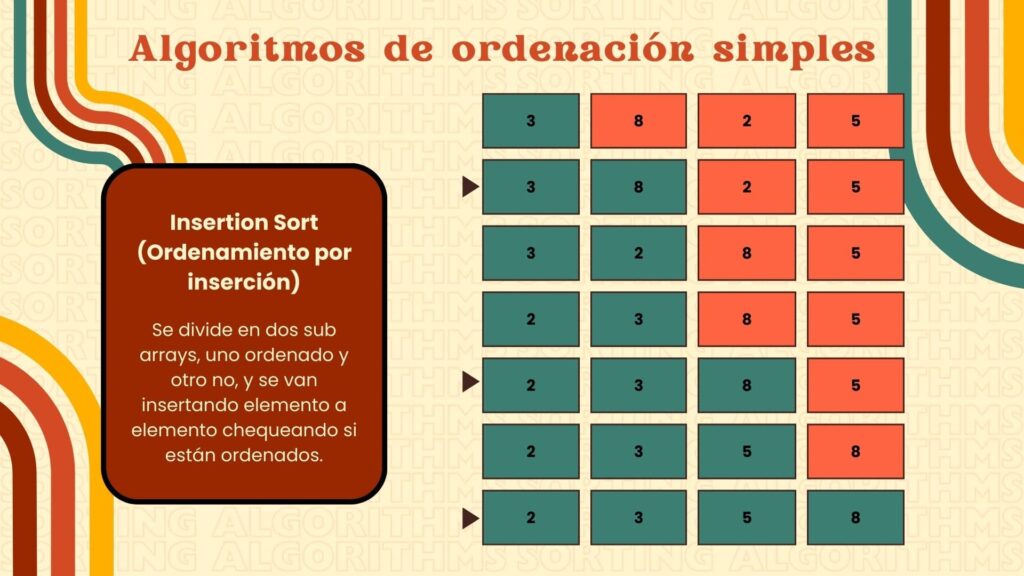
¿Qué es Insertion Sort y cómo funciona?
Insertion Sort construye la lista ordenada elemento por elemento. En cada iteración, toma un elemento de la parte desordenada y lo inserta en la posición correcta dentro de la parte ordenada. Su comportamiento es similar a cómo una persona ordenaría un mazo de cartas en la mano.
Complejidad temporal de Insertion Sort
Insertion Sort tiene un rendimiento variable según el estado inicial de la lista:
¿Cuándo Insertion Sort es mejor que Bubble Sort y Selection Sort?
Insertion Sort es más eficiente en listas pequeñas y casi ordenadas, ya que su mejor caso es O(n), lo que lo hace más rápido que los otros dos en estos escenarios. Además, tiene menos intercambios que Bubble Sort y suele ser más eficiente que Selection Sort en listas parcialmente ordenadas.
Estos algoritmos son ampliamente utilizados en aplicaciones reales gracias a su rendimiento confiable, especialmente cuando se trabaja con grandes volúmenes de datos.
Merge Sort sigue el paradigma de divide y vencerás. Divide recursivamente la lista en mitades hasta que cada sublista tenga un solo elemento, y luego las vuelve a unir de forma ordenada. Esta estrategia permite ordenar eficientemente sin necesidad de comparar cada elemento con todos los demás.
Ventajas:
Desventajas:

QuickSort también usa divide y vencerás, pero con un enfoque diferente. Elige un pivote y reorganiza la lista para que todos los elementos menores queden a la izquierda y los mayores a la derecha. Luego repite el proceso recursivamente.
La elección del pivote afecta directamente su rendimiento. Si se elige mal (por ejemplo, siempre el menor o mayor), el algoritmo puede volverse ineficiente.
| Criterio | Merge Sort | QuickSort |
|---|---|---|
| Complejidad (peor caso) | O(n log n) | O(n²) |
| Uso de memoria | Mayor (no in-place) | Menor (in-place) |
| Estabilidad | Estable | No estable |
| Rendimiento en la práctica | Consistente | Muy rápido |
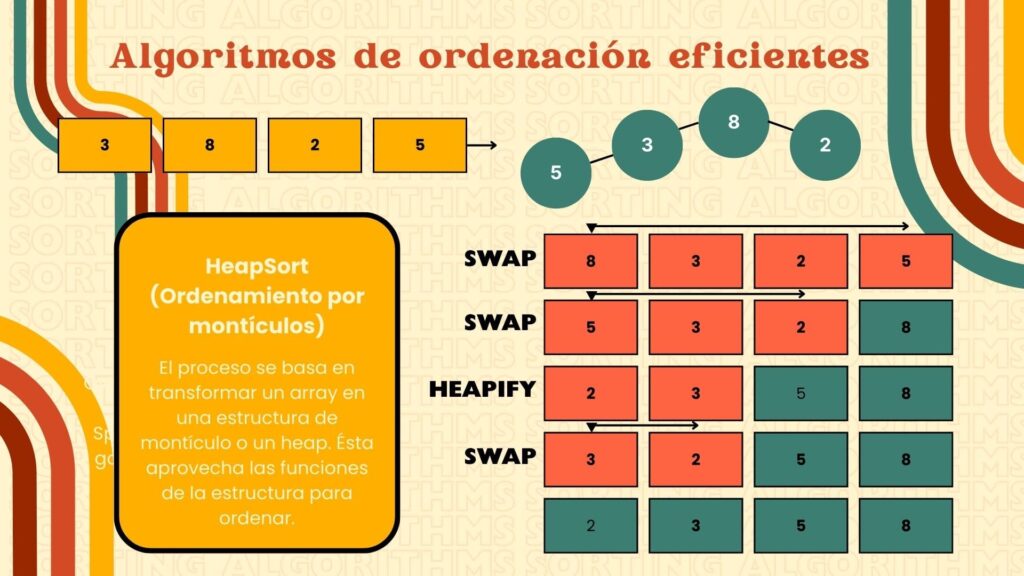
HeapSort se basa en una estructura llamada heap binario, que permite acceder rápidamente al mayor (o menor) elemento. El algoritmo transforma el arreglo en un heap y luego extrae el valor máximo repetidamente, reordenando el heap en cada paso hasta dejar la lista ordenada.
Los algoritmos de ordenación no comparativos forman una categoría especial que no se basa en comparar elementos entre sí. En lugar de eso, utilizan características internas de los datos, como sus dígitos o valores exactos. Son extremadamente eficientes cuando se aplican en los contextos adecuados, superando incluso a los algoritmos comparativos más conocidos en términos de velocidad.

Counting Sort ordena elementos contando cuántas veces aparece cada valor dentro de un rango específico. A partir de ese conteo, reconstruye la lista en orden.
Ejemplo práctico:
Si tenemos una lista con valores entre 0 y 9, el algoritmo crea un arreglo auxiliar para registrar cuántas veces aparece cada número. Luego, usa esa información para ubicar los elementos en sus posiciones correctas.
Esto significa que es muy rápido cuando el rango (k) es pequeño en relación con la cantidad de datos (n).
Ventajas:
Limitaciones:

Radix Sort trabaja sobre los dígitos individuales de los números, desde el dígito menos significativo hasta el más significativo (o al revés). Es ideal para ordenar números enteros de varios dígitos.
🔍 Ejemplo práctico:
Para una lista de números entre 100 y 999, Radix Sort puede ordenar primero por la unidad, luego por la decena y finalmente por la centena. Esto se repite hasta que todos los dígitos han sido procesados.
Es lineal si k es pequeño, lo que suele ser cierto en muchas aplicaciones prácticas.
| Criterio | Radix Sort | Counting Sort |
|---|---|---|
| Tipo de dato | Números enteros con varios dígitos | Enteros simples en un rango limitado |
| Rango de valores | Funciona aunque el rango sea amplio | Necesita un rango acotado y pequeño |
| Velocidad | Alta, si k (dígitos) es pequeño | Muy alta, si k (valores únicos) es bajo |
| Espacio en memoria | Puede requerir más espacio auxiliar | También usa espacio extra, pero menos |
| Aplicaciones típicas | Ordenar identificadores, claves, etc. | Edad de personas, calificaciones, etc. |
Elegir el algoritmo de ordenación adecuado puede marcar una gran diferencia en el rendimiento, especialmente cuando se trata de trabajar con grandes volúmenes de datos. A continuación, analizamos y comparamos los algoritmos más populares en base a su complejidad y casos de uso.
| Algoritmo | Mejor caso | Promedio | Peor caso | Uso recomendado |
|---|---|---|---|---|
| Bubble Sort | O(n) | O(n²) | O(n²) | Listas pequeñas y casi ordenadas |
| Selection Sort | O(n²) | O(n²) | O(n²) | Pequeñas listas sin restricciones de rendimiento |
| Insertion Sort | O(n) | O(n²) | O(n²) | Listas pequeñas y casi ordenadas |
| Merge Sort | O(n log n) | O(n log n) | O(n log n) | Grandes listas, ordenación estable |
| QuickSort | O(n log n) | O(n log n) | O(n²) | Ordenación rápida en la mayoría de los casos |
| HeapSort | O(n log n) | O(n log n) | O(n log n) | Cuando se necesita ordenación sin memoria extra |
| Counting Sort | O(n + k) | O(n + k) | O(n + k) | Datos con rango pequeño y conocido |
| Radix Sort | O(nk) | O(nk) | O(nk) | Datos numéricos con pocos dígitos |

Los algoritmos de ordenación no son estáticos: con el tiempo, se han desarrollado optimizaciones inteligentes y variantes híbridas para mejorar su rendimiento según el tipo de datos y el entorno de ejecución.
Bubble Sort puede mejorarse usando una bandera (flag) que verifique si se realizaron intercambios durante una pasada. Si no se hicieron cambios, significa que la lista ya está ordenada y el algoritmo puede detenerse anticipadamente.
Esto reduce la complejidad en el mejor caso a O(n), en lugar de hacer todas las pasadas innecesarias.
Insertion Sort suele buscar la posición de inserción en O(n). Pero si se reemplaza esa búsqueda lineal por una búsqueda binaria, se reduce ese tiempo a O(log n).
Aun así, la complejidad total sigue siendo O(n²) por los desplazamientos de elementos, pero gana eficiencia en listas parcialmente ordenadas.
Los algoritmos híbridos combinan las fortalezas de varios métodos para adaptarse mejor a distintas situaciones.
Introsort (Introduced Sorting) comienza usando QuickSort por su rapidez promedio, pero si detecta que la recursión se está profundizando demasiado (lo que indica un caso desfavorable), cambia automáticamente a HeapSort, garantizando una complejidad O(n log n) incluso en el peor caso.
Este enfoque lo hace altamente robusto y confiable, y por eso es el algoritmo por defecto en la STL (Standard Template Library) de C++.
Timsort es un algoritmo híbrido que combina Insertion Sort y Merge Sort.
Este enfoque hace que Timsort sea increíblemente eficiente para listas parcialmente ordenadas, que son comunes en aplicaciones reales.
Por eso es el algoritmo de ordenación predeterminado en Python y Java.

Los algoritmos de ordenación no solo son importantes en teoría: tienen un rol crucial en el rendimiento de sistemas reales, desde bases de datos hasta inteligencia artificial.
Los sistemas de bases de datos utilizan ordenación para mejorar la eficiencia de consultas y operaciones complejas:
En el campo del aprendizaje automático, ordenar datos es una etapa crítica del preprocesamiento:
La ordenación también es esencial en disciplinas como las telecomunicaciones y la visión por computadora:
No todos los algoritmos de ordenación son iguales, y elegir el equivocado puede transformar una tarea simple en un cuello de botella que frena todo tu sistema.
Lo que parece un detalle técnico es, en realidad, una decisión crítica.
¿Ordenas una lista pequeña casi organizada? Insertion Sort será tu aliado.
¿Procesas millones de registros en tiempo real? Necesitas la potencia de Quick Sort o la estabilidad de Merge Sort.
¿Tienes claves enteras con un rango limitado? Counting Sort podría resolverlo más rápido que cualquier método basado en comparaciones.
Elegir sin entender el contexto —por costumbre, por lo que viste en clase o porque “funciona”— puede provocar tiempos de espera innecesarios, consumir recursos del servidor, o arruinar la experiencia del usuario.
Y no estamos exagerando: la eficiencia de tu software, tus resultados en una entrevista técnica o incluso la calidad de una app que vendas, pueden depender de esa elección.
En esta guía no solo te explicamos cada algoritmo con claridad. Vamos más allá: te damos la lógica para saber cuándo aplicar cada uno, por qué unos son mejores que otros según el caso y cómo evitar errores comunes que muchos desarrolladores cometen, incluso en producción.

A lo largo de este artículo, hemos explorado los algoritmos de ordenación más comunes y sus aplicaciones en diferentes escenarios. Estos algoritmos son esenciales para mejorar el rendimiento en diversas áreas, desde el procesamiento de grandes volúmenes de datos hasta la optimización de sistemas en inteligencia artificial, bases de datos y redes.
Si estás comenzando en el mundo de los algoritmos de ordenación, te recomiendo seguir este orden de aprendizaje para obtener una base sólida y luego avanzar a temas más complejos:
Para seguir aprendiendo sobre algoritmos de ordenación y otros temas de algoritmos y estructuras de datos, aquí tienes algunos recursos recomendados:
Recuerda que el aprendizaje de algoritmos de ordenación es solo el principio. Estos principios fundamentales de ordenación te proporcionarán las bases para abordar problemas más complejos, como algoritmos de búsqueda, algoritmos de grafos, programación dinámica y más.
Si estás desarrollando un software o trabajando en proyectos de inteligencia artificial, bases de datos o redes, estos algoritmos son herramientas esenciales para mejorar el rendimiento y eficiencia de tus sistemas.
¡Sigue explorando y practicando, y verás cómo tu comprensión de los algoritmos de ordenación te ayudará a resolver problemas más complejos con mayor eficacia!



Un algoritmo de ordenación es un conjunto de instrucciones diseñado para organizar los elementos de una lista o arreglo en un orden específico, como ascendente o descendente. Se utilizan para mejorar la eficiencia en la búsqueda de datos, análisis, visualización y optimización de recursos en muchos programas y sistemas.
El ordenamiento burbuja (Bubble Sort) suele ser el más recomendado para principiantes por su simplicidad. Compara elementos adyacentes y los intercambia si están en el orden incorrecto, repitiendo este proceso hasta que la lista esté ordenada. Aunque no es el más eficiente, ayuda a comprender conceptos básicos como comparaciones e intercambios.
Un algoritmo estable mantiene el orden original de los elementos con valores iguales, mientras que uno inestable puede cambiar ese orden. Por ejemplo, si dos productos tienen el mismo precio y se ordenan por precio, un algoritmo estable los dejará en el mismo orden en que estaban originalmente.
QuickSort suele ser uno de los algoritmos más rápidos en la práctica debido a su enfoque “divide y vencerás”, especialmente con grandes volúmenes de datos. Sin embargo, su rendimiento puede verse afectado si los datos están muy desordenados o ya casi ordenados, en cuyo caso Merge Sort puede ser más predecible y seguro.
Se deben considerar varios factores como:
Tamaño de los datos.
Si los datos ya están parcialmente ordenados.
Uso de memoria (in-place o no).
Necesidad de estabilidad.
Velocidad en el peor, mejor y promedio de los casos.
Cada algoritmo tiene fortalezas y debilidades según el contexto.
“Per aspera ad astra.”
A través de las dificultades hasta las estrellas.
© 2025 DevWebers. All Rights Reserved.